
20130727 New Indexer Preview Releases
A fairly major overhaul of the indexing and caching sub-systems of SVEditor has been underway for the past few months. Overall functionality and quality has reached a point where we are ready for input from the community.
New Indexer Highlights
The new indexer strategy is a fairly significant departure from the current index strategy, and enables some key new features:
- Overall indexing performance is roughly 2x faster
- Improved performance on slow filesystems
- Support for the use of included SV file fragments
- Support for multi-file compilation unit
- Improved support for incremental indexing
- Support for viewing the include hierarchy
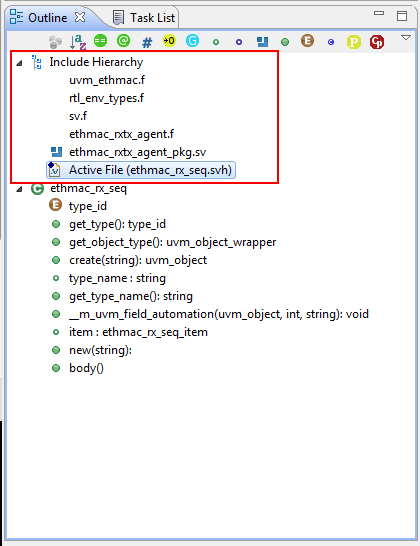
Trying Out the New Indexer
Unfortunately, it isn't possible to select which indexer and cache is used at runtime, so an Eclipse preference can't be used to switch on the new indexer. Consequently, two builds of SVEditor are now being made for each release:
- The 'normal' build with the new indexer turned off
- A 'testing' build with the new indexer turned on
The easiest way to try out the new indexer is to add the following update site to your Eclipse installation and install the current 'testing' release.
http://sveditor.org/update_testing
Much has changed in the new indexer architecture, so bugs are to be expected. Please file bugs using the Sourceforge site, and note which version of the 'testing' release you are using.
Indexer Changes
For those interested in more detail about what actually is changing, here is the next level of detail. The changes essentially break down as follows:
- File-processing and representation changes
- Cache architecture changes
- Incremental indexing changes
File-processing Changes
In the current index architecture, each indexed file is essentially expected to stand on its own. Indexing is a two-step process:
- Create a pre-processed view of each file (starting from the root) and identify included files
- Parse all files (root and included)
While this file-processing strategy makes it easier to take a collection of files and determine which files should be processed first, there are drawbacks:
- Each file is processed twice, which slows things down on a slow filesystem
- Included file fragments are not supported, since each file is processed individually
- The infrastructure is improper to support multi-file compilation unit parsing
In the new architecture, each root file is processed in a single step just as it would be by a compiler. Consequently:
- Each file is read only once
- Included file fragments are supported, since the parser only sees the fully pre-processed root file
- The index infrastructure is designed to support multi-file compilation unit mode
Note: Since root files are the fundamental quantity managed by the new index, any time a non-root file view is needed it must be constructed. Consequently, this is an area where bugs can be encountered. Look out for:
- Core functionality bugs, such as null pointer exceptions
- Performance issues -- re-creating a non-root file view can be expensive, so it is done as infrequently as possible
Cache Architecture Changes
The SVEditor indexer uses a file-backed cache to store the pre-processed and parsed representations of source and argument files. This backing cache enables SVEditor to manage codebases whose parsed representation would not fit in memory. It also enables SVEditor to not re-parse all files when Eclipse is re-started.
In the current release of SVEditor, each index has a single cache. The cache is implemented by multiple files (one per cached element) on the filesystem. While this system is reasonably efficient when running on a fast filesystem, this system is inefficient on a slow filesystem due to the number of individual file accesses needed to access the cache. In addition, the fact that each index has a single cache limits the amount of multi-threaded indexing that can be done.
The new cache architecture utilizes a centralized cache filesystem where all cached-element data is stored within a series of large files. This is anticipated to have a positive impact on performance on filesystems where accessing many files is slow.
In addition, each index is now permitted to have multiple cache instances. This enables multi-threaded asynchronous indexing while not blocking user interactions. In the new index architecture, each index instance has an active cache that is used to service requests. Incremental indexing activity now utilizes a separate cache that is only merged back to the active cache once the index activity is complete. This minimizes the amount of time the index is 'locked' during an index operation.
Incremental Indexing Changes
The current indexer is very conservative about re-indexing. In most cases, whenever a file changes the full index will be rebuilt. Obviously, with a large number of files, this can slow things down significantly.
The new indexer is hooked into the Eclipse builder subsystem, and receives detailed information on file changes. Based on the list of changes, it then computes a plan for updating the index. Currently, a change to a SystemVerilog source file results in the index re-indexing whichever root file included the source file. Currently, a change to an argument file results in the entire index being rebuilt (though this will changed to be more incremental in the future).
The benefit, of course, is that the indexer does less work when files change.